All I wanted was a simple code search, I ended up in a ranking theory rabbit hole
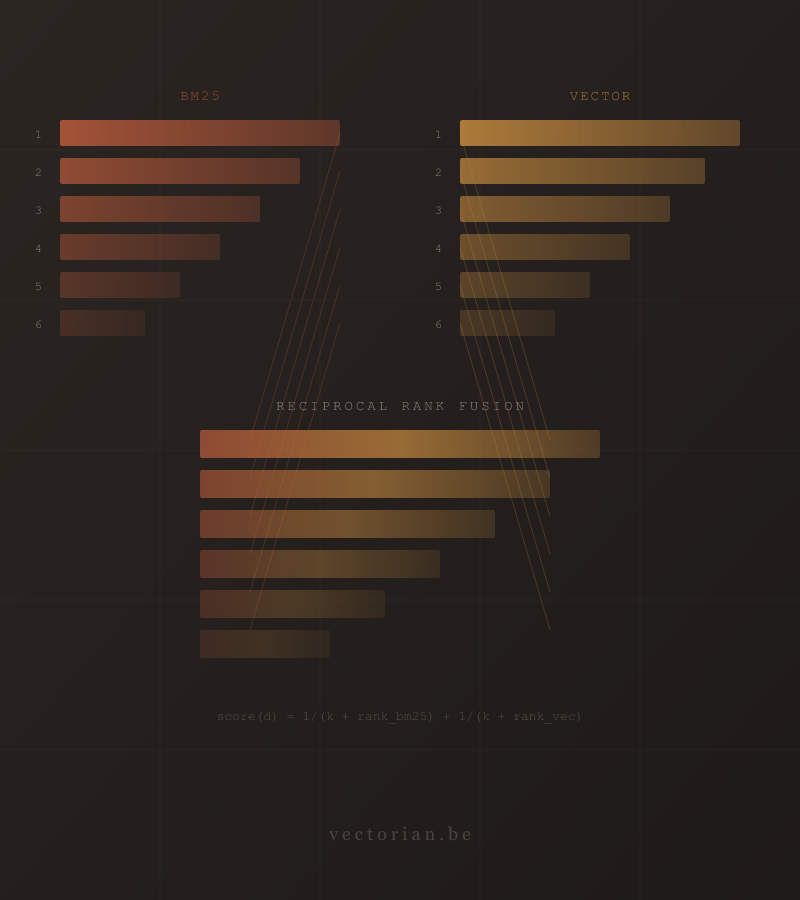
I built an on-device hybrid search engine that combines BM25 and vector retrieval with Reciprocal Rank Fusion. Reranking metrics suggested a learned linear fusion model would outperform RRF, but end-to-end evaluation showed otherwise. This article explains why the model matched baseline behavior and what to improve next.